understand the distinction between predictive and prescriptive analytics
understand the role of prescriptive analytics within sport
understand the limitations of prescriptive analytics
be familiar with some some common approaches to prescriptive analytics
Note
Remember, this section (like the previous one) is intended to provide you with a general overview and ‘flavour’ of some key ideas and processes that will be covered in more detail in the Research Methods module in Semester Two.
There is no need at this stage to fully understand these concepts.
20.2 Introduction
Definition of ‘prescriptive analytics’
In the previous section, we explored the concept of ‘predictive analytics’. In this section, we’re moving on to think about prescriptive analytics.
Predictive and prescriptive analytics can be thought of as two different approaches to data analytics, each with its own purpose and output. They can be conducted separately, or sequentially, depending on the purpose of your analysis. Usually, they would take place after completing the descriptive analysis.
As we discussed in the previous section, predictive analytics uses statistical techniques to predict future outcomes based on historical data. It answers the question: “What is likely to happen in the future, based on what I already know”?
Predictive analytics doesn’t tell you what action to take, but it can be used to forecast potential outcomes if certain factors are present. For example, it can predict the likelihood of a player getting injured based on current workload and injury history.
In contrast, prescriptive analytics goes a step further than predictive analytics by recommending actions to take for optimal outcomes. It answers the question: “What should we do?”, which is often the thing that coaches, managers and owners are most interested in!
Prescriptive analytics uses techniques such as optimisation, simulation, and decision-tree algorithms to suggest actions that will take advantage of the predictions in your model.
So for example, prescriptive analytics might suggest that a strategy of reducing the player’s training intensity, or increasing rest days, is the best approach. In a business context, it might identify the optimal pricing strategy for season tickets to maximise future sales.
In essence, while predictive analytics forecasts what might happen in the future, prescriptive analytics advises on what actions to take to achieve the best possible outcome.
You may find it helpful to read the following journal article before continuing.
20.3 Development
Prescriptive analytics is a form of advanced analytics that examines data or content to determine what actions should be taken to achieve a particular goal.
It’s distinguished from descriptive analytics, which summarises raw data and presents it in an understandable form, and predictive analytics, which forecasts future possibilities.
Some potential use-cases for predictive analytics are described below.
Strategic decision-making
Prescriptive analytics can be an invaluable tool for strategic decision-making in sport. It uses algorithms and computational models to suggest the best course of action based on an array of complex data.
For example, the German football team at the 2014 FIFA World Cup worked with SAP to create a ‘match insights’ software. This prescriptive tool processed data about the team’s tactics and their opponents, helping to inform crucial decisions that ultimately led to their triumph.
Player performance optimisation
Prescriptive analytics also plays a vital role in optimising player performance and maintaining player health. By analysing factors such as player workload, sleep patterns, and biomechanics, sports teams can make proactive decisions to boost performance and prevent injuries.
The Golden State Warriors, an NBA team, used prescriptive analytics to determine the optimum rest days for their players, reducing injuries and enhancing their performance on the court.
Fan engagement
Enhancing the fan experience is another potential application of prescriptive analytics in sport. Sporting organisations can analyse fan behaviour, social media engagement, and ticket sales to provide a more engaging and personalised fan experience.
20.4 Challenges and Limitations of Prescriptive Analytics
Despite its potential, prescriptive analytics is not without challenges. Technological barriers, data privacy issues, and the sheer volume and complexity of data can impede implementation. Furthermore, the ethical implications of data collection and use that we’ve discussed before cannot be ignored. IMO, the use of prescriptive analytics should complement, not replace, human judgment and intuition.
20.5 Procedures for Prescriptive Analytics
As noted above, prescriptive analytics builds on descriptive and predictive analytics to suggest a course of action based on predictions. It involves the application of advanced analytics techniques like optimisation and simulation algorithms, decision-tree models, and complex systems dynamic models, which we’ll introduce below.
Again, don’t worry too much about the detail here. This is intended simply to give you an insight into some of the more advanced analytical techniques we’ll cover later in this module, and in B1705.
For example, to solve an ‘optimisation problem’ - finding the best solution from a range of possible solutions - we can use the lpSolve package in R to perform linear programming.
In an optimisation problem, we’re basically trying to find the best possible outcome, which could mean getting the highest or lowest result. We do this by picking values from a given set of options and using them in a specific calculation or formula. We keep doing this until we find the best answer!
# An example of prescriptive analysis in Rrm(list =ls()) ## create a clean environment# Install the lpSolve package if not installedif(!require(lpSolve)) install.packages('lpSolve')
Loading required package: lpSolve
Warning: package 'lpSolve' was built under R version 4.4.1
Here, the code is trying to find the best values for two variables, [x1] and [x2], so as to get the highest value of the expression (3x1)+(2x2), but the values chosen must also meet two conditions (constraints) related to how big or small [x1] and [x2] can be.
Key Components of Prescriptive Analytics
Optimisation
Optimisation, within the context of prescriptive analytics, is a mathematical approach used to determine the best allocation of limited resources to achieve a specific objective.
The main aim is to maximise desirable factors (like profit, goals scored, or aerobic efficiency) and/or minimise undesirable ones (like injury, points dropped, or waste).
Simulation
Simulation is another powerful tool used in prescriptive analytics that allows decision-makers to model complex scenarios and systems to understand potential outcomes, risks, and opportunities.
It involves the creation of a mathematical model that represents a real-world system, and then running experiments on that model to predict how the system will behave under different circumstances.
In prescriptive analytics, simulation is used to predict the consequences of different decisions and to suggest the best course of action. It’s particularly useful in situations that are too costly, risky, or time-consuming to experiment in real life, or when there’s a need to make predictions about complex systems with a high degree of uncertainty.
By running simulations, the analyst can gain insights into potential outcomes and make data-informed decisions that optimise results.
Decision analysis
Decision analysis is a systematic, quantitative, and visual approach to addressing and informing strategic decisions. As a concept within prescriptive analytics, it uses mathematical models, statistical methods, and logic to help decision-makers choose among a set of alternatives.
The primary aim of decision analysis is to provide clarity on the potential outcomes of different choices and to assess their impact on specified goals. It’s especially useful when decisions involve significant complexity or uncertainty.
More on decision trees
Decision trees are a key tool in predictive analytics, and they are used to model the relationships between several input variables and a target variable. In essence, they provide a structured methodology for making decisions based on data.
In the context of predictive analytics, decision trees are used for both classification and regression tasks. A classification tree is used when the outcome is a categorical variable, such as predicting whether a team will win or not. A regression tree, on the other hand, is used when the outcome is a continuous variable, such as predicting the number of points scored.
The decision tree algorithm operates by creating binary splits in the data. At each node of the tree, the algorithm chooses a feature and a split point that best separates the data according to a certain criterion. For classification tasks, this criterion is often the Gini impurity or entropy, which measure the homogeneity of the target variable within the subsets. For regression tasks, the split point is typically chosen to minimise the variance of the target variable within the subsets.
A major advantage of decision trees is their interpretability. The logic of a decision tree can be easily visualised and understood, even by people without a strong background in data science. This makes decision trees a popular choice for applications where interpretability is important, such as credit scoring or medical diagnosis.
However, decision trees also have some limitations. They can easily overfit or underfit the data, so it’s important to tune the complexity of the tree using techniques such as pruning. Decision trees are also sensitive to small changes in the data, which can lead to different splits and potentially different predictions.
Despite these limitations, decision trees are a fundamental building block for more complex models, such as random forests and gradient boosting machines, which use ensemble methods to combine the predictions of multiple decision trees, thereby improving the predictive performance and robustness.
There is more coverage on decision trees, and their implementation in R, below (Section 20.8.1).
20.6 Application in sport: Player selection and resource allocation
Let’s imagine we’re an analyst for a professional basketball team, and we’re tasked with optimising the player lineup for the upcoming season. Our objective is to maximise the overall rating of our lineup, subject to a budget constraint (as the team can only afford to pay a certain total amount in player salaries).
For simplicity, let’s assume we’re choosing from 5 players, with the following ratings and salaries:
Player 1: Rating = 85, Salary = £15 million
Player 2: Rating = 92, Salary = £20 million
Player 3: Rating = 88, Salary = £18 million
Player 4: Rating = 80, Salary = £10 million
Player 5: Rating = 83, Salary = £12 million
We’ll also assume that our total budget for player salaries is £50 million.
Here’s how we can solve this problem using the lpSolve package in R:
# Load the lpSolve packagelibrary(lpSolve)# Set the coefficients of the objective functionf.obj <-c(85, 92, 88, 80, 83) # Set the coefficients of the constraintsf.con <-matrix(c(15, 20, 18, 10, 12), nrow=1)# Set the type of constraintsf.dir <-c("<=")# Set the right-hand side coefficientsf.rhs <-c(50)# Run the linear programming modeloptimum_lineup <-lp("max", f.obj, f.con, f.dir, f.rhs, all.bin =TRUE)# Print the optimal solutionprint(optimum_lineup$solution)
[1] 0 1 1 0 1
The lp function is used to define and solve the linear programming problem. The “max” argument indicates that we’re maximizing the objective function. The all.bin = TRUE argument specifies that our decision variables (the players we choose) are binary - in other words, we either choose a player (1) or we don’t (0).
The output of the lp function is a list that includes the optimal values of the decision variables, which can be accessed using optimum_lineup$solution.
In this case, the output will be a vector indicating which players to choose in order to maximize the team’s overall rating while staying within the budget constraint. For example, if the output is (1, 1, 0, 1, 1), this would mean we should choose players 1, 2, 4, and 5.
20.7 Application in sport: Monte Carlo simulation
What is Monte Carlo Simulation?
Monte Carlo simulation is a computational technique used to model the probability of different outcomes in a process that cannot easily be predicted due to the intervention of random variables. By running simulations many times over, one can calculate the probability of a specific outcome.
In a sporting context, think of it as running a particular game or match 10,000 times in a computer, each time with slightly different variables (e.g., player performances, environmental conditions), and then seeing what percentage of those simulations results in a win, a loss, or a draw.
Basic Steps in a Monte Carlo Simulation
Define a model: Understand the problem and the factors influencing the outcome.
Generate random inputs: Use random number generators to produce inputs for the model.
Perform a deterministic computation: Run the model with the random inputs.
Collect and analyze the results: After a large number of iterations, analyze the statistical properties of the outcomes.
Monte Carlo Simulation in R
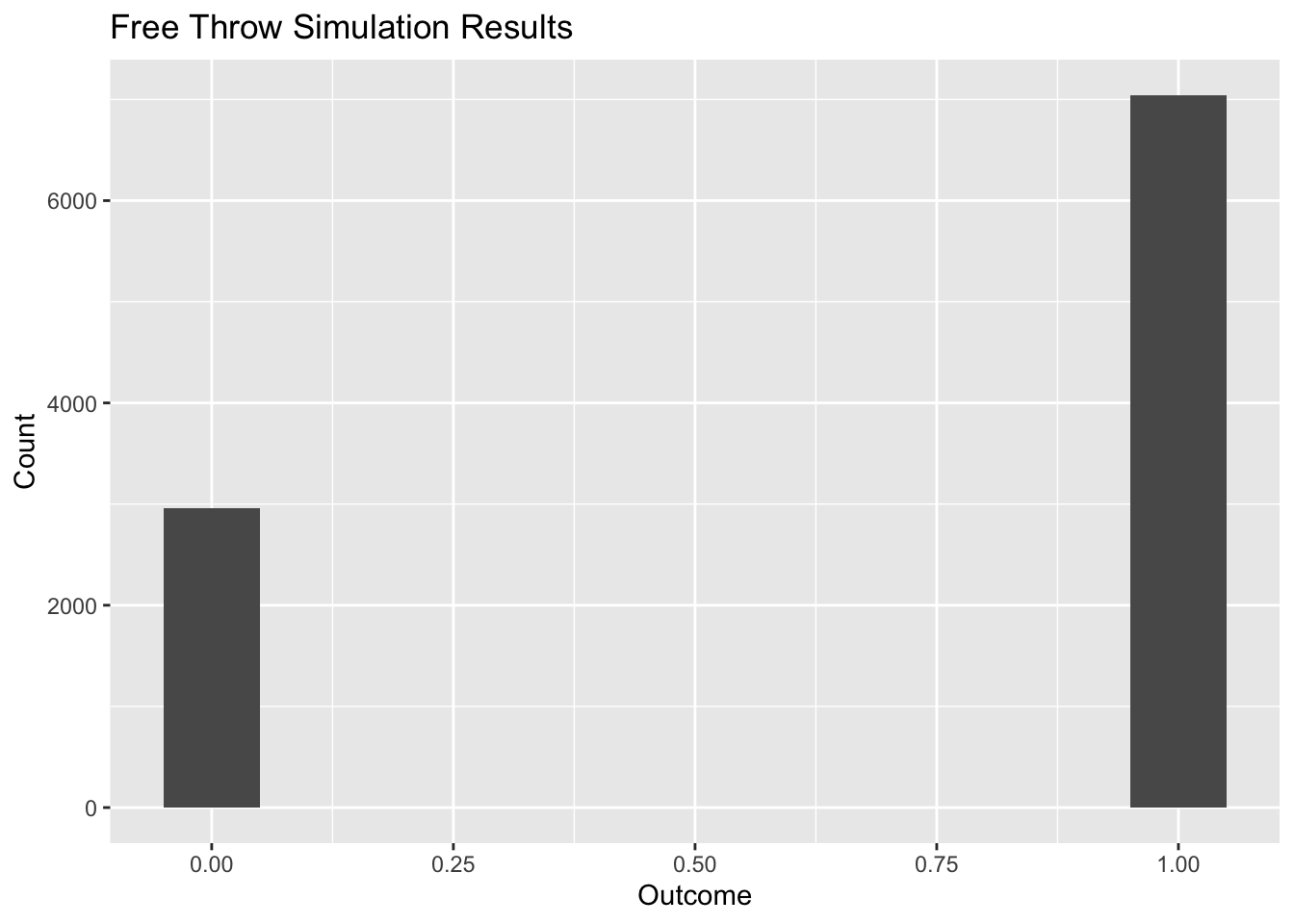
We’ll simulate the outcome of a free throw in basketball. We assume a player has a 70% chance of making a shot.
# Load necessary packageslibrary(ggplot2)# Monte Carlo simulation functionsimulate_free_throw <-function(n) { shots_made <-rbinom(n, 1, 0.7)mean(shots_made)}# Run the simulation 10,000 timesn_simulations <-10000results <-replicate(n_simulations, simulate_free_throw(1))# Visualise the resultsdf <-data.frame(success = results)ggplot(df, aes(x = success)) +geom_histogram(binwidth =0.1) +labs(title ="Free Throw Simulation Results", x ="Outcome", y ="Count")
In this example, we can observe that roughly 70% of the outcomes result in a successful shot (or close to that), reinforcing the player’s free throw percentage.
20.8 Application in sport: Decision Analysis
Decision trees
As we know, sport data analytics involves extracting meaningful insights from vast amounts of sports-related data. It assists teams, athletes, and organizations in making better decisions. One popular tool in this field is the ‘Decision Tree’, a machine learning technique that makes predictions based on asking a series of questions.
A Decision Tree is a flowchart-like structure wherein each node represents a feature (attribute), each branch symbolises a decision rule, and every leaf stands for an outcome. The goal is to create a model that predicts the value of a target variable based on decision rules inferred from data features.
We’ll start with a simple example in R using the rpart package, which is specifically designed for decision trees:
# Install and load necessary packageif(!require(rpart)) install.packages('rpart')
Loading required package: rpart
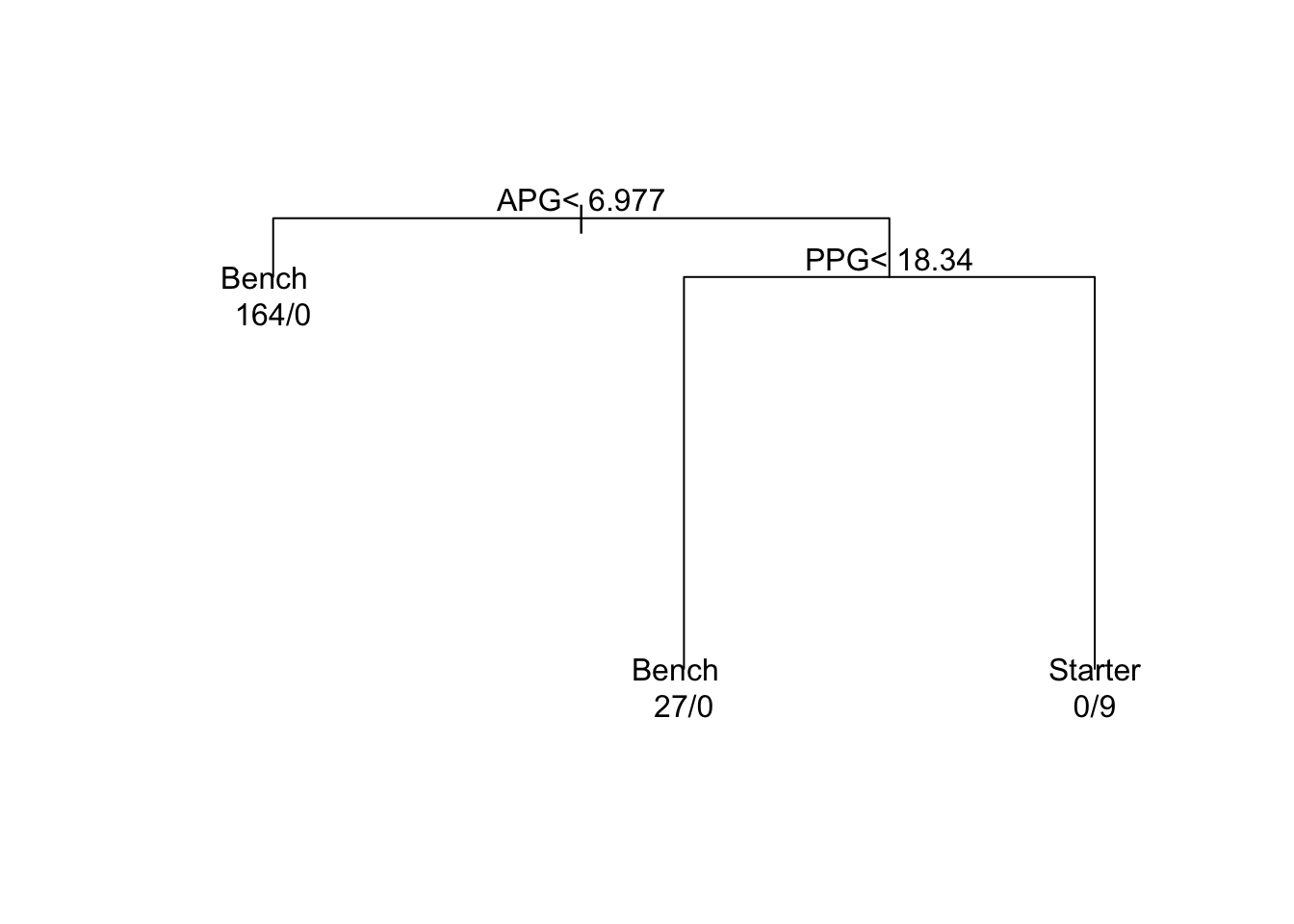
library(rpart)# Generate some synthetic dataset.seed(123) # To ensure reproducibilityn <-200# Number of playersPPG <-rnorm(n, mean=15, sd=5)APG <-rnorm(n, mean=5, sd=2)Role <-ifelse(PPG >=18& APG >=7, "Starter", "Bench")players_data <-data.frame(PPG, APG, Role)# Create the Decision Treetree_model <-rpart(Role ~ PPG + APG, data=players_data, method="class") # this tells R the 'algorithm' we wish to implement# Print the decision tree summaryprint(tree_model)
# Visualise the treeplot(tree_model, margin=0.1)text(tree_model, use.n=TRUE)
This decision tree classifies 200 players into two roles: “Starter” and “Bench”. Here’s a basic interpretation of the tree’s outcome:
If a player’s average points per game (PPG) are equal to or greater than a certain threshold, say 18, the tree might further check the player’s average assists per game (APG).
Among those with high PPG, if their APG is also above a certain level, say 7, they are likely to be classified as a “Starter”. If not, they might still be placed on the bench.
Players with PPG below the initial threshold are more often than not categorized as “Bench” players, regardless of their APG.
This decision tree suggests that while both PPG and APG are important, a player’s scoring ability (PPG) is the primary factor determining their role. However, when PPG is high, their playmaking ability (APG) can further influence the decision.
In this example, we have trained our model on the entire dataset. Usually, we prefer to split our model into training and testing sub-sets. We’ll cover all of this in B1705.